Welcome all users to the Adipome database.
This database encompasses multi-omics data from the past fifteen years concerning various time points during the differentiation of the mouse 3T3-L1 adipocyte cell line, including RNA-seq, ChIP-seq, DNase-seq, Hi-C, ATAC-seq, and GRO-seq. It aims to characterize adipocyte differentiation in vitro across different omics layers, with the goal of constructing a comprehensive epigenetic regulatory atlas of adipocyte differentiation in vitro.
Below is guidance on using this website:
Using RNA-seq as an example:
Navigate to Browse & Download → RNA-seq → Sample ID. Select the appropriate dataset based on your desired differentiation time point and treatment conditions and then select the accession number of interested sample (A).

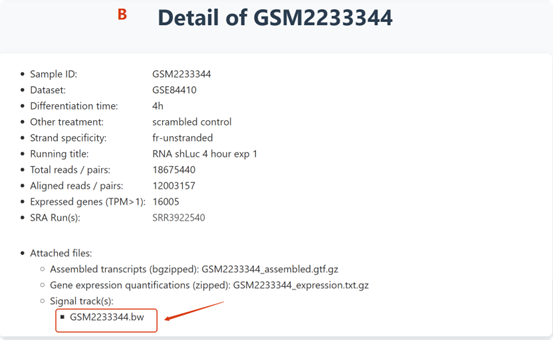
Users can browse detailed metadata and quality control indicators on the details page. For each data type, we provide downloadable files of commonly used final data formats (B).
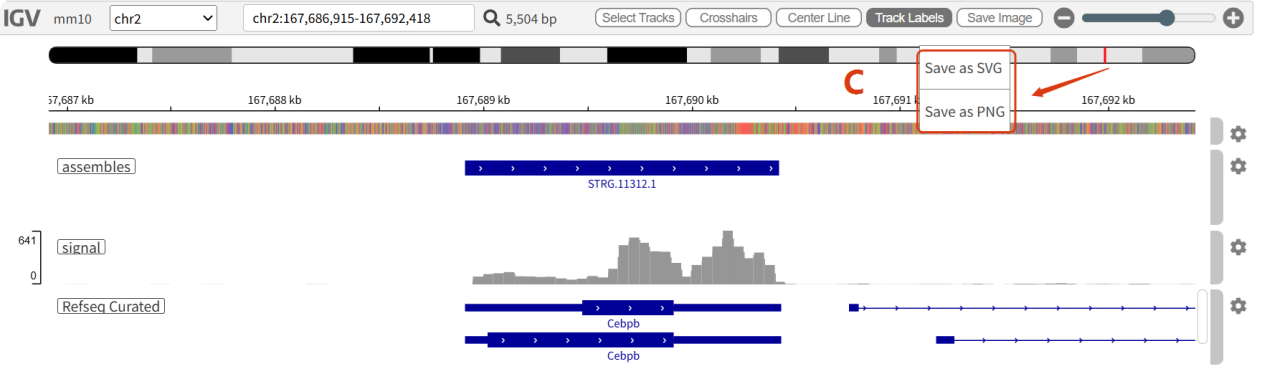
On the details page, we have implemented simple visualizations, allowing users to interact with the genome browser component at the bottom of the page to quickly browse areas of interest. The visualization results can also be saved (C).
To ensure data quality and consistency, all omics data in the database were processed using standardized bioinformatics pipelines. Below is a brief overview of the key steps for each data type.
Qualified libraries were fed into fastp for low quality reads and adapter removal. Clean reads were aligned to the mm10 reference genome using Hisat2. Gene-level expression was quantified using Stringtie. Signal tracks for visualization were generated using